Columbia University, Center for Smart Streetscapes (NSF ERC) | Summer 2024 Advisor: Prof. Zoran Kostic | ZKLab
Dense 3D reconstruction of urban intersections typically requires multiple synchronized, calibrated cameras. In this project, I investigate whether meaningful reconstruction is possible using two unsynchronized cameras with ~180° viewpoint separation, mismatched resolutions, and no shared infrastructure, reflecting realistic smart-city constraints.
View from Go Pro
View from the CCTV on 2nd floor
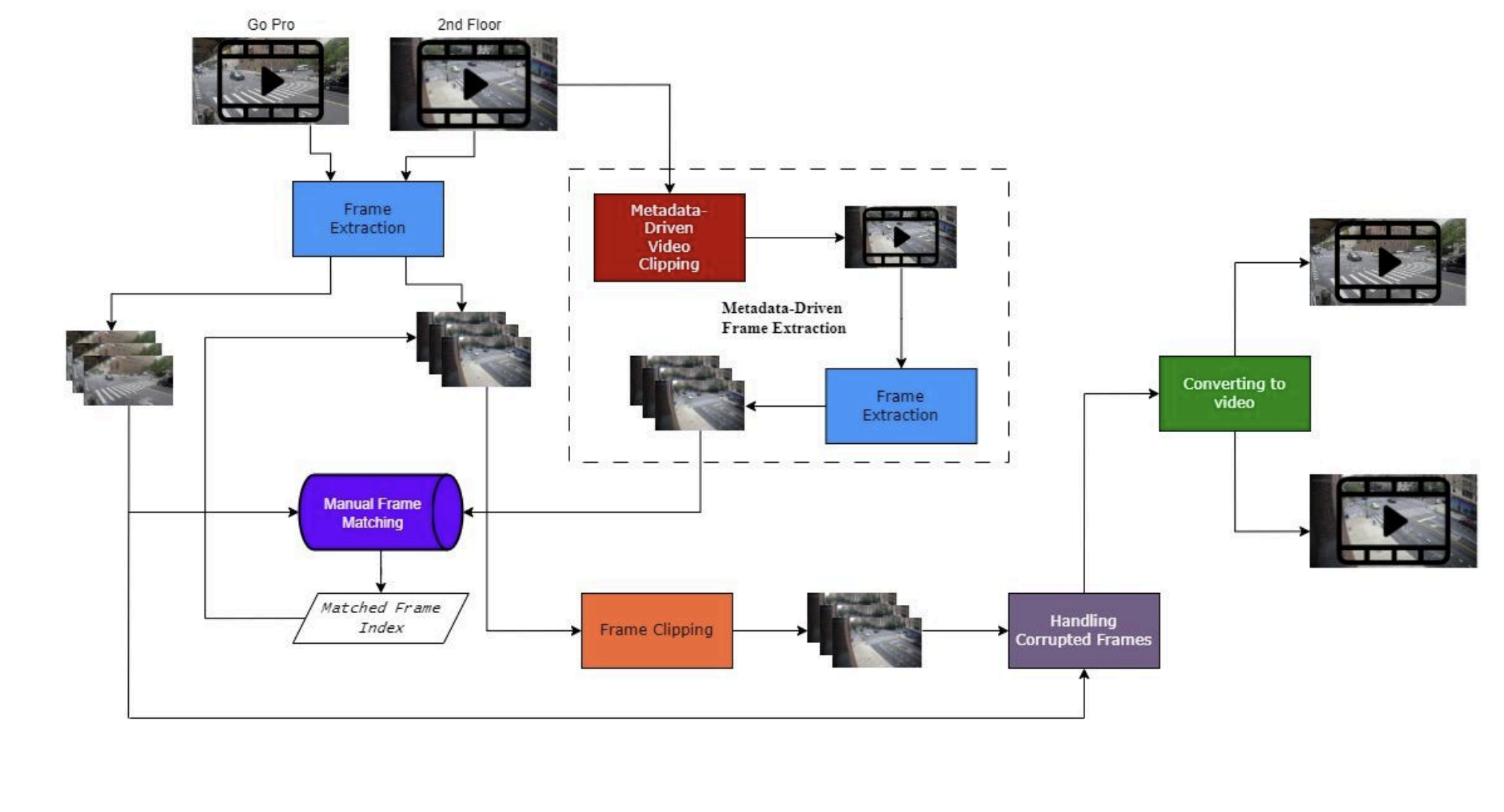
I developed a temporal alignment pipeline recovering frame-level synchronization entirely in software (metadata bootstrapping → buffer extraction → manual frame matching → synchronized corruption removal), then evaluated DUSt3R for multi-view reconstruction with automatic pose estimation and Metric3D for monocular depth as a per-view baseline. DUSt3R recovered coarse intersection geometry across the extreme baseline without manual calibration; Metric3D produced finer per-view depth but required manual cross-view registration.
To enable this, I developed a fully software-based temporal alignment pipeline to recover frame-level synchronization despite clock drift, extreme viewpoint differences, and lack of shared visual features. Notably, standard feature-matching methods (e.g., SIFT) fail in this regime due to minimal cross-view correspondence and dynamic scene elements.
Data Preprocessing Pipeline
DUSt3R successfully registered the opposing viewpoints and recovered coarse intersection geometry without manual calibration, but sacrificed fine-grained detail. Metric3D produced higher-resolution per-view depth maps but required manual alignment for cross-view fusion. This complementary trade-off motivated a proposed hybrid pipeline using depth-conditioned diffusion models to bridge the viewpoint gap, which led directly to the subsequent depth-conditioned augmentation project.
Code & Data: Available upon request through Prof. Zoran Kostic's lab (proprietary to CS3/COSMOS testbed)
The Problem
Multi-view 3D reconstruction assumes either hardware-synchronized cameras or post-hoc temporal alignment from shared visual features. Neither holds when cameras face each other across a wide baseline with no shared clock.
How few cameras do you need to reconstruct a 3D traffic intersection — and what happens when those cameras share no infrastructure at all?
Views from 4 cameras
The CS3 COSMOS testbed at Columbia already had a working pipeline: four networked CCTV cameras with synchronized internal clocks, all feeding into DUSt3R for dense 3D point cloud generation. The reconstruction worked well — four overlapping views with known timing produce clean geometry.
4D reconstruction of all 4-cameras from the COSMOS testbed (DUSt3R, ViT-Large). All cameras are network-synchronized CCTVs.
But deploying four synchronized cameras at every intersection doesn't scale. The real question is whether you can get comparable reconstruction from fewer, cheaper, completely unsynchronized cameras — the kind of setup you'd actually deploy in the field.
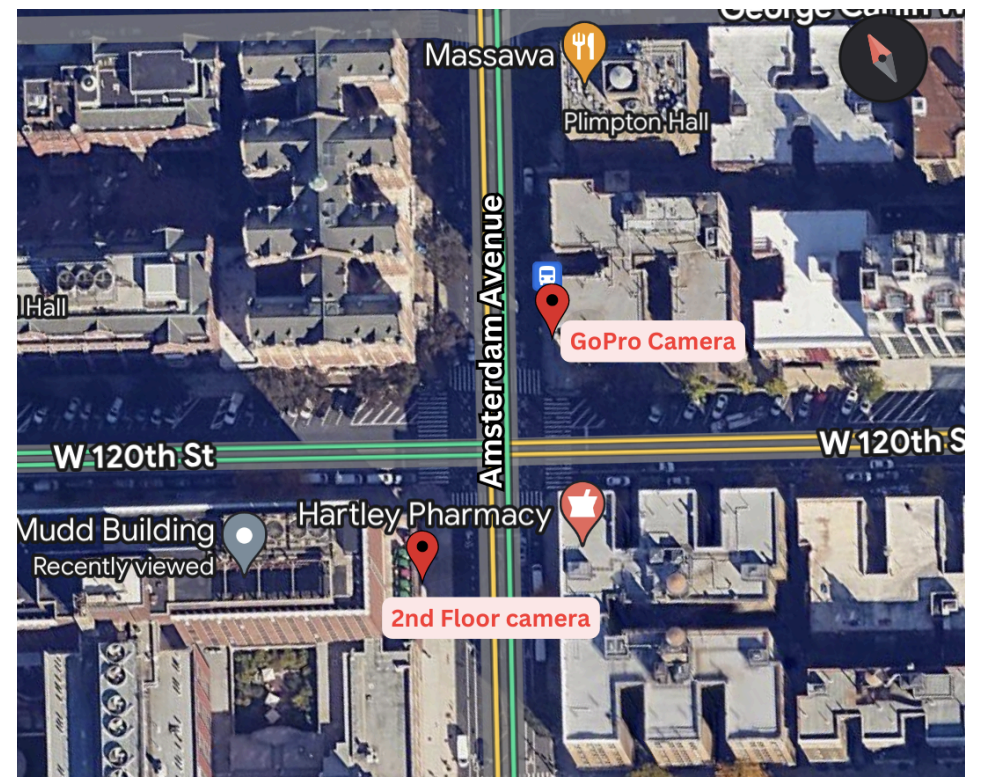
Our Setup: Two Cameras, Zero Shared Infrastructure
We placed two cameras at diagonally opposite corners of the 120th St & Amsterdam Ave intersection:
Camera 1: 2nd floor of the Mudd building at Columbia, 4K resolution, AVI format, 2-4 hour continuous recording via the COSMOS testbed
Camera 2: GoPro HERO5 Black, strapped to a pole at 10 feet above the road, 1080p, MP4 format, ~90 minutes of battery life
Position of cameras in the intersection.
A frame (top) from the second floor building and its corresponding frame temporally synchronized (bottom).
The cameras face each other with nearly 180° viewpoint separation and a significant elevation difference. They share no network, no clock, no synchronization signal. The GoPro's FAT32 SD card splits recordings into 17-minute, ~3.7GB chunks. The two video streams have different resolutions, different codecs, different frame rates, and no temporal correspondence.
This is deliberately harder than the 4-camera setup — and it mirrors real-world smart city constraints where camera placement is dictated by available infrastructure (building facades, existing poles), not optimized for reconstruction.
Temporal Synchronization Without Hardware
With no shared clock, the entire temporal alignment had to be recovered by designing a pipeline:
Step 1 — Rough alignment from metadata: Camera timestamps provided an approximate overlap estimate, but clock drift between devices meant this was only accurate to within several minutes.
Step 2 — Buffer extraction: A 20-minute window (±10 min around the rough estimate) was extracted from the longer 2nd-floor footage, narrowing the search space from hours to minutes.
Step 3 — Manual frame matching: Within this buffer, exact frame-level correspondence was established through manual comparison. Automated feature matching (SIFT) fails here — nearly opposite viewpoints with an elevation change share too few visual features. Moving objects (vehicles, pedestrians) appear so different from the two perspectives that they confuse matchers rather than helping them.
Step 4 — Synchronized corruption handling: Corrupted frames (visual artifacts, encoding errors, dropped frames) were detected in both streams. When frame n is flagged in either stream, it is removed from both — preserving frame-level alignment across the full dataset.
Data Preprocessing Pipeline
The output: two cleaned, frame-synchronized video sequences from extreme viewpoints, with no shared infrastructure beyond the alignment pipeline itself.
3D Reconstruction: Two Approaches, One Trade-Off
DUSt3R (multi-view): Takes the synchronized frame pairs and jointly estimates camera poses and dense 3D pointmaps using a ViT-Large backbone. The key advantage: DUSt3R infers camera intrinsics and extrinsics during alignment — no calibration needed. Despite the ~180° baseline and elevation change, it recovers the intersection's coarse spatial structure: road plane, crosswalks, vehicles, and building facades.
DUSt3R reconstruction of the same scene / frame from 2 different views
Metric3D (monocular): Produces per-frame metric depth maps from each view independently using canonical camera space transformation. The depth maps capture finer detail — individual vehicles, lane markings, surface geometry — but each view reconstructs in its own coordinate system. Fusing two Metric3D outputs requires manual extrinsic alignment, which is fragile and time-consuming when the viewpoints are nearly opposite.
Metric3D reconstruction of the same scene
The core trade-off: DUSt3R automates the geometric registration but loses fine detail. Metric3D preserves detail but can't auto-register views with extreme baselines. Neither alone gives you both precision and automation.
Code & Data: Available upon request through Prof. Zoran Kostic's lab (proprietary to CS3/COSMOS testbed)