The Problem
Gastrointestinal cancers affect over 28 million people annually, and conventional endoscopy misses roughly one in four lesions. The reason: standard endoscopes rely on color contrast to identify abnormal tissue, but many clinically significant lesions are defined by their topography — they protrude from the surrounding surface — not their color. The lighting strategies of conventional endoscopes actually minimize topographic contrast, making these lesions harder to detect.
If you could recover the 3D surface geometry of internal organs during endoscopy — pixel-wise depth and surface normals — you could detect lesions that color imaging misses. This project built the hardware, generated synthetic training data, trained deep learning models, and systematically evaluated reconstruction across progressively more realistic capture configurations — all targeting photometric stereo for endoscopic 3D reconstruction.
Why Photometric Stereo?
Photometric stereo recovers surface geometry by observing a static scene under varying illumination. Unlike structure-from-motion, which requires camera motion and feature matching, photometric stereo works from a fixed viewpoint — ideal for endoscopy, where:
- The camera is constrained inside a narrow tube with limited movement
- Organ tissue has limited surface texture, making feature matching unreliable
- Dense depth maps are needed at every pixel, not just at sparse feature points
- No rigid-body assumptions about the scene are required
The challenge: endoscopic scenes violate standard photometric stereo assumptions. The light sources are extremely close to the surface (near-field), the depth range is large relative to the light-source distance, and per-pixel lighting direction varies significantly across the image. Classical methods assume uniform, distant illumination — that breaks completely in this setting.
Building the Imaging System
Design 1
Benchtop capture setup. Left: DSLR camera (later replaced with FLIR) with 24-LED ring. Right: Close-up of the ring.
Benchtop setup: A ring of 24 LEDs with 4cm radius mounted around a DSLR camera (later replaced with a FLIR machine vision camera for finer control over gain, grayscale, and exposure), with objects placed at 15-17cm. This served as the controlled baseline — far-field enough that classical photometric stereo assumptions approximately hold. Calibrated light source directions using a specular probe, mapping highlight positions to incident illumination vectors through analytical reflection constraints.
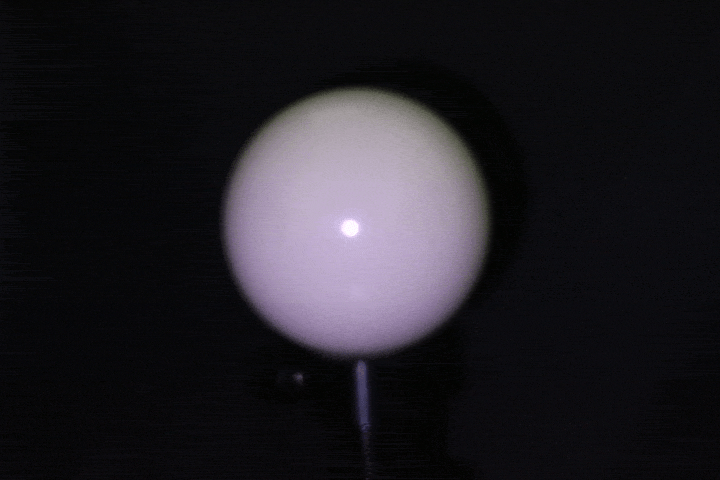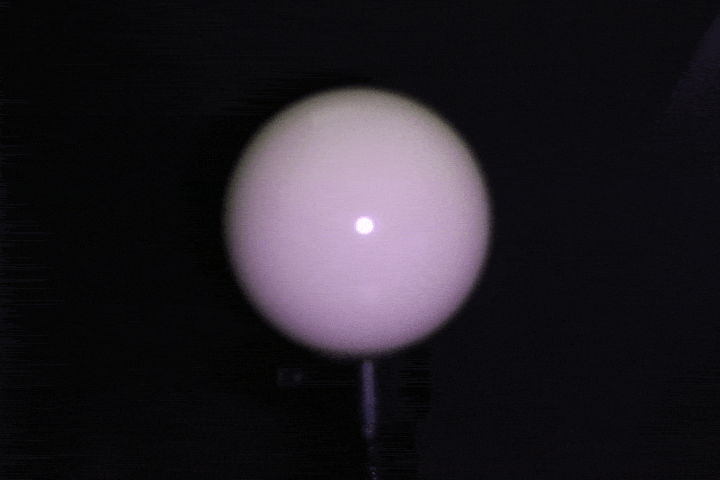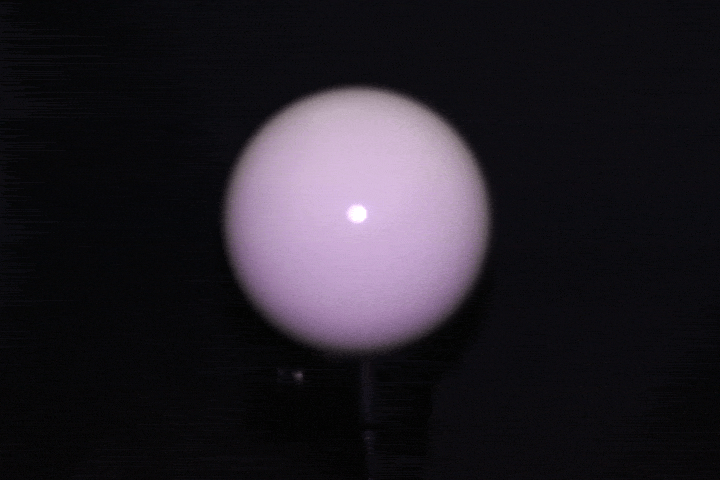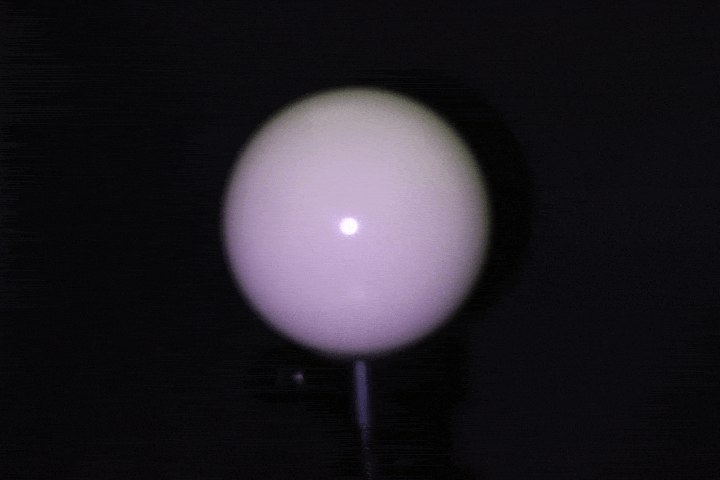
Light calibration using a specular ball.
Results
Testing conventional (non-learning-based) photometric stereo on the benchtop setup produced accurate results for simple objects like the bunny, but broke down on endoscopic scenes. With only 3 light sources available through the endoscope's light channel, the scene's large depth range and the camera's extreme proximity to the surface meant per-pixel lighting directions varied drastically — violating the assumption that all pixels see light from the same direction.

Bunny — input

Bunny — predicted normals & albedo
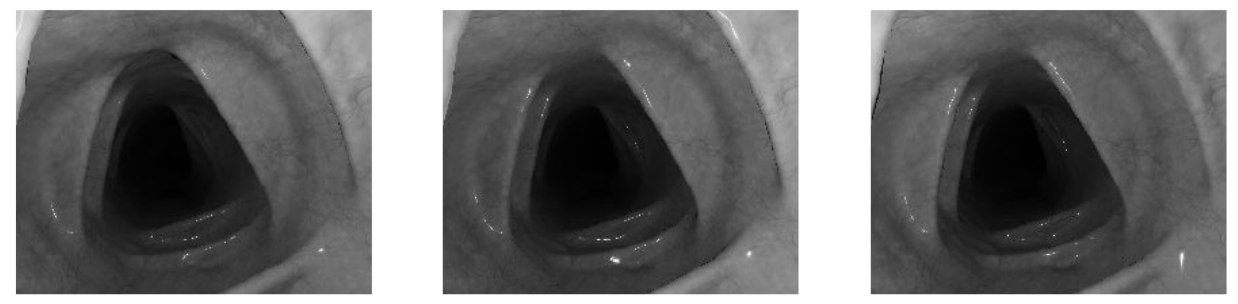
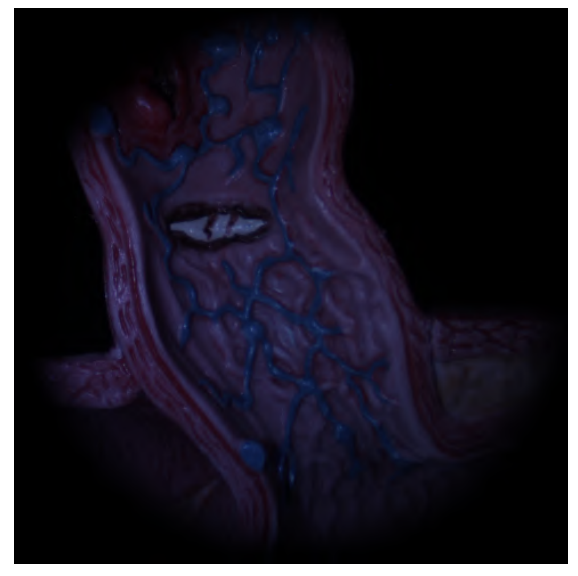
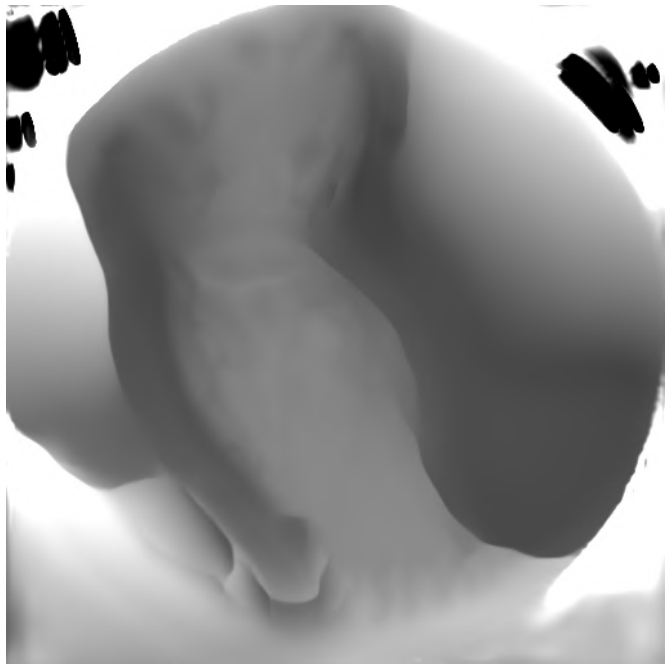
Endoscopic scene — input
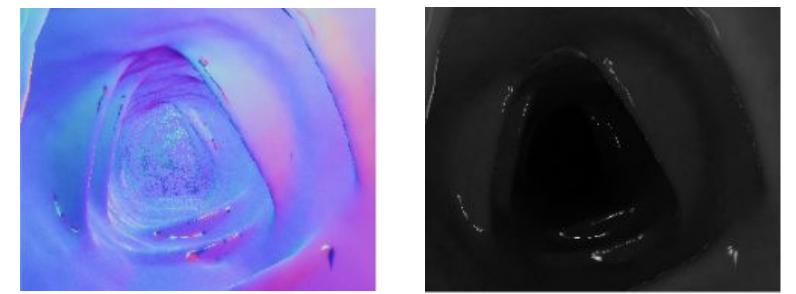
Endoscopic scene — poor normals (assumption violated)
Conventional photometric stereo results. Top: Bunny under varying illumination — reconstruction is accurate. Bottom: Endoscopic scene — only 3 light sources at extreme proximity break the uniform illumination assumption, producing poor normals.
Design 2
Endoscope prototype capture setup: A Raspberry Pi camera mounted on a 3D-printed stand I designed, with 4 LEDs positioned around it, oriented downward so the object sits below. This configuration was built specifically so it mimics how an endoscope looks and functions and served as the physical reference for the Unity rendering pipeline to approach the near-field geometry using deep learning.

Ex-vivo tissue capture setup — Raspberry Pi camera and LEDs on a custom 3D-printed stand, object placed below.
Rendering Synthetic Training Data in Unity
To train a learning-based approach that could handle near-field geometry, I built a rendering pipeline in Unity to generate synthetic endoscopic scenes with ground truth. The virtual setup modeled the ex-vivo capture geometry — a camera surrounded by 4 LEDs, with LED positions randomly perturbed within a bounded region at each rendering to make the network robust to calibration errors. Each scene was rendered under 4 lighting conditions, producing 5,244 scenes with pixel-wise surface normals and depth — including both clear organ surfaces and scenes with polyps.
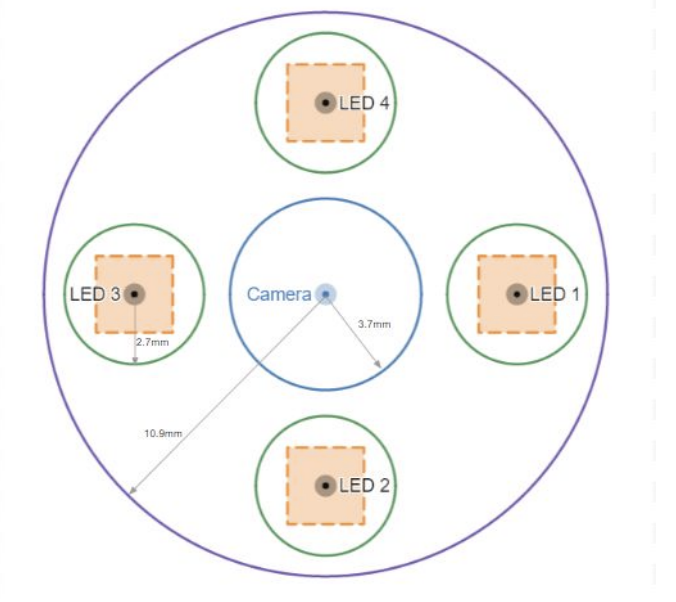
The outer circle in the centre is for the camera. The other 4 smaller circles are for LEDs and the square in each circle is the region from which the LED positions are randomly sampled. The random sampling is done to make the neural network robust to errors in the light positions.
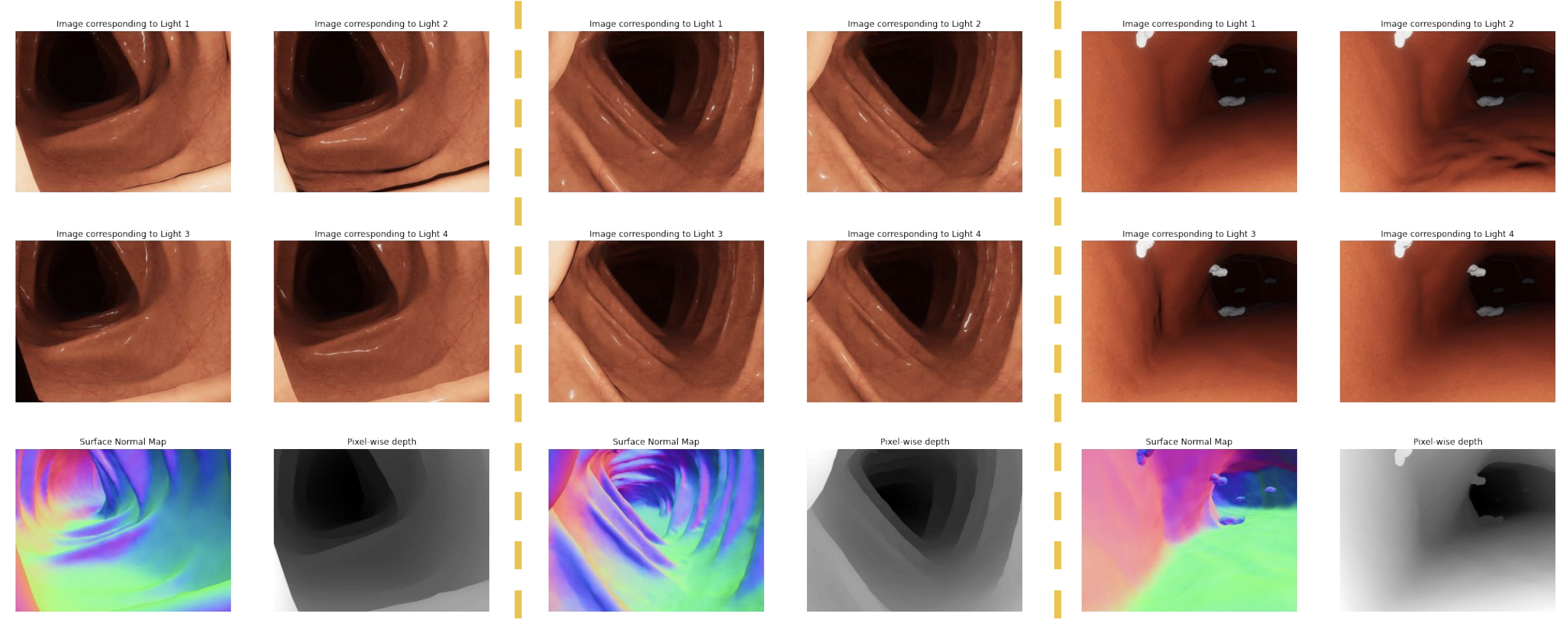
Examples from the synthetic dataset. Each column shows a scene under 4 lighting conditions (top two rows), with ground-truth surface normal maps and pixel-wise depth (bottom row). Dataset includes 5,244 scenes covering clear organ surfaces and polyps.
Training the Near-Field Photometric Stereo Model
I used Fast Light-Weight Near-Field Photometric Stereo (Lichy et al., CVPR 2022), a learning-based approach that explicitly models per-pixel lighting. The method trains two recursive networks: one predicts surface normals, the other predicts depth conditioned on those normals. At each recursion step, the resolution doubles and per-pixel lighting parameters (direction and attenuation) are recalculated from the current depth estimate.

Predicted surface normals, predicted depth, and 3D reconstruction of the bunny.

Input images under different lights with predicted surface normals and depth.
With the trained model in hand, I systematically evaluated it across three hardware configurations, each reducing the light-source radius and object distance to progressively approach real endoscopic conditions.
Configuration 1: Benchtop with FLIR Camera
24-LED ring, 4cm radius. Objects at 15-17cm. FLIR camera replacing the earlier DSLR for finer imaging control. 10 images selected from 24 available. This far-field configuration produced the cleanest results — dense 3D reconstructions closely matched the real object geometry for objects including the Stanford bunny, owl figurine, and vase.